数据库分组聚合Group by用法理解
评分
关于group by的理解,为什么不能够select * from Table group by id,而只能select某一个列或者某个列的聚合函数?多个字段的group by怎么来理解?关键字where、group by、having、order by的书书写顺序和执行顺序又是怎样的?下面先来分析下group by的分组聚合原理。
先来看下表1,表名为test:

表1
执行如下SQL语句:
1 2 |
|
你应该很容易知道运行的结果,没错,就是下表2:

表2
可是为了能够更好的理解“group by”多个列“和”聚合函数“的应用,我建议在思考的过程中,由表1到表2的过程中,增加一个虚构的中间表:虚拟表3。下面说说如何来思考上面SQL语句执行情况:
1.FROM test:该句执行后,应该结果和表1一样,就是原来的表。
2.FROM test Group BY name:该句执行后,我们想象生成了虚拟表3,如下所图所示,生成过程是这样的:group by name,那么找name那一列,具有相同name值的行,合并成一行,如对于name值为aa的,那么<1 aa 2>与<2 aa 3>两行合并成1行,所有的id值和number值写到一个单元格里面。

3.接下来就要针对虚拟表3执行Select语句了:
(1)如果执行select *的话,那么返回的结果应该是虚拟表3,可是id和number中有的单元格里面的内容是多个值的,而关系数据库就是基于关系的,单元格中是不允许有多个值的,所以你看,执行select * 语句就报错了。
(2)我们再看name列,每个单元格只有一个数据,所以我们select name的话,就没有问题了。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的。
(3)那么对于id和number里面的单元格有多个数据的情况怎么办呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如cout(id),sum(number),而每个聚合函数的输入就是每一个多数据的单元格。
(4)例如我们执行select name,sum(number) from test group by name,那么sum就对虚拟表3的number列的每个单元格进行sum操作,例如对name为aa的那一行的number列执行sum操作,即2+3,返回5,最后执行结果如下:
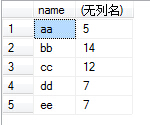
(5)group by 多个字段该怎么理解呢:如group by name,number,我们可以把name和number 看成一个整体字段,以他们整体来进行分组的。如下图
(6)接下来就可以配合select和聚合函数进行操作了。如执行select name,sum(id) from test group by name,number,结果如下图:
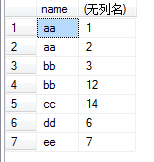
当一个查询语句同时出现了where,group by,having,order by的时候,书写顺序是:
SELECT
FROM
WHERE (先过滤单表/视图/结果集,再JOIN)
GROUP BY
HAVING (WHERE过滤的是行,HAVING过滤的是组,所以在GROUP之后)
ORDER BY
其对应的执行顺序是:
执行where对全表数据做筛选,返回第1个结果集。
针对第1个结果集使用group by分组,返回第2个结果集。
针对第2个结果集中的每1组数据执行select,有几组就执行几次,返回第3个结果集。
针对第3个结集执行having进行筛选,返回第4个结果集。
针对第4个结果集排序。
需要注意having和where的用法区别:
1.having只能用在group by之后,对分组后的结果进行筛选(即使用having的前提条件是分组)。
2.where肯定在group by 之前,即也在having之前。
3.where后的条件表达式里不允许使用聚合函数,而having可以。
4.having后只能跟group by后边字段条件 或者 非group by(group by 字段也可以使用聚合函数)字段的聚合函数条件(按组查询);
另外注意,使用count(列名)函数计算行数时,当某列出现null值的时候,count(*)仍然会计算,但是count(列名)不会。
(完)
- 点赞举报收藏